import fastcore
import pandas as pd
import pathlib
from fastcore.all import *
from fastcore.imports import *
import os
import sys
import sklearn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score, cross_val_predict, KFold, train_test_split
from sklearn.metrics import ConfusionMatrixDisplay, accuracy_score, plot_confusion_matrix, confusion_matrix
from IPython.display import display
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoderBlubook Bulldozer
Shows the usage of aiking library on a kaggle dataset
Import public packages
Import private packages
is_kaggle = 'kaggle_secrets' in sys.modulesif is_kaggle:
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
os.environ['KAGGLE_USERNAME'] = user_secrets.get_secret("kaggle_username")
if not os.environ['KAGGLE_USERNAME']: raise Exception("Please insert your Kaggle username and key into Kaggle secrets")
os.environ['KAGGLE_KEY'] = user_secrets.get_secret("kaggle_key")
github_pat = user_secrets.get_secret("GITHUB_PAT")
!pip install -Uqq git+https://{github_pat}@github.com/Rahuketu86/aiking
else:
from aiking.data.external import *
path = untar_data("kaggle_competitions::bluebook-bulldozer-remix");
print(path.ls())[Path('/AIKING_HOME/data/bluebook-bulldozer-remix/bluebook-bulldozer-remix.zip'), Path('/AIKING_HOME/data/bluebook-bulldozer-remix/Data Dictionary.xlsx'), Path('/AIKING_HOME/data/bluebook-bulldozer-remix/Train'), Path('/AIKING_HOME/data/bluebook-bulldozer-remix/TrainingData'), Path('/AIKING_HOME/data/bluebook-bulldozer-remix/Valid')]from aiking.ml.structured import *Read the Dataset
data_dir = pathlib.Path(os.getenv('DATA_DIR', "/kaggle/input"));
path = data_dir/"bluebook-bulldozer-remix"
path.ls()(#5) [Path('/kaggle/input/bluebook-bulldozer-remix/bluebook-bulldozer-remix.zip'),Path('/kaggle/input/bluebook-bulldozer-remix/Data Dictionary.xlsx'),Path('/kaggle/input/bluebook-bulldozer-remix/Train'),Path('/kaggle/input/bluebook-bulldozer-remix/TrainingData'),Path('/kaggle/input/bluebook-bulldozer-remix/Valid')]df_train = pd.read_csv(path/"Train/Train.csv", low_memory=False,parse_dates=['saledate'], infer_datetime_format=True); df_train.head()
df_test = pd.read_csv(path/"Valid/Valid.csv", parse_dates=['saledate'], infer_datetime_format=True); df_test.head()| SalesID | MachineID | ModelID | datasource | auctioneerID | YearMade | MachineHoursCurrentMeter | UsageBand | saledate | fiModelDesc | ... | Undercarriage_Pad_Width | Stick_Length | Thumb | Pattern_Changer | Grouser_Type | Backhoe_Mounting | Blade_Type | Travel_Controls | Differential_Type | Steering_Controls | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1222837 | 902859 | 1376 | 121 | 3 | 1000 | 0.0 | NaN | 2012-01-05 | 375L | ... | None or Unspecified | None or Unspecified | None or Unspecified | None or Unspecified | Double | NaN | NaN | NaN | NaN | NaN |
| 1 | 1222839 | 1048320 | 36526 | 121 | 3 | 2006 | 4412.0 | Medium | 2012-01-05 | TX300LC2 | ... | None or Unspecified | 12' 4" | None or Unspecified | Yes | Double | NaN | NaN | NaN | NaN | NaN |
| 2 | 1222841 | 999308 | 4587 | 121 | 3 | 2000 | 10127.0 | Medium | 2012-01-05 | 270LC | ... | None or Unspecified | 12' 4" | None or Unspecified | None or Unspecified | Double | NaN | NaN | NaN | NaN | NaN |
| 3 | 1222843 | 1062425 | 1954 | 121 | 3 | 1000 | 4682.0 | Low | 2012-01-05 | 892DLC | ... | None or Unspecified | None or Unspecified | None or Unspecified | None or Unspecified | Double | NaN | NaN | NaN | NaN | NaN |
| 4 | 1222845 | 1032841 | 4701 | 121 | 3 | 2002 | 8150.0 | Medium | 2012-01-04 | 544H | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | Standard | Conventional |
5 rows × 52 columns
Modelling
Define categories ordering
max_n_cat = 0
cat_dict = get_cat_dict(df_train, max_n_cat=max_n_cat)
display_cat(cat_dict)| 0 | 1 | |
|---|---|---|
| 0 | UsageBand | [High, Low, Medium] |
| 1 | fiModelDesc | [100C, 104, 1066, 1066E, 1080, 1080B, 1088, 1088CK, 1088LT, 1088TTL, 10B, 10C, 10DG, 110, 1105, 110S, 110TLB, 110Z, 110Z-2, 112, 112E, 112F, 115, 1150, 1150B, 1150BLGP, 1150C, 1150D, 1150E, 1150ELT, 1150G, 1150GLGP, 1150GLT, 1150H, 1150HLGP, 1150HLT, 1150HWT, 1150K, 1150KLGPSERIES3, 1150KWT, 1150KXLT, 1150KXLTIII, 115SRDZ, 115Z, 115ZIII, 115ZIV, 115ZIV-2, 115ZV, 116, 1166, 118, 1187C, 1188, 1188LC, 1188P, 118B, 118C, 11B, 11C, 12, 120, 120B, 120C, 120CLC, 120D, 120E, 120G, 120H, 120HNA, 120LC, 120M , 125, 125A, 125B, 125C, 125CKBNA, 1280, 1280B, 1288, 12E, 12F, 12G, 12H, 12HNA, 12JX, 130, 1300, 1300D, 130G, 130LC, 130LX, 1340XL, 135, 135C, 135CRTS, 135H, 135HNA, 135MSR SPIN ACE, 135SR, 135SRLC, ...] |
| 2 | fiBaseModel | [10, 100, 104, 1066, 1080, 1088, 10DG, 11, 110, 1105, 112, 115, 1150, 116, 1166, 118, 1187, 1188, 12, 120, 125, 1280, 1288, 130, 1300, 1340, 135, 137, 14, 140, 1400, 143, 1450, 15, 150, 1500, 153, 155, 1550, 16, 160, 1600, 163, 165, 1650, 166, 17, 170, 1700, 1737, 1740, 175, 1750, 1760XL, 17ZTS, 18, 1800, 1818, 1825, 1830, 1835, 1838, 1840, 1845, 185, 1850, 190, 1900, 198, 20, 200, 2000, 2022, 2026, 2040, 2042, 2044, 205, 2050, 2054, 2060, 2060XL, 2064, 2066, 2070, 2074, 2076, 208, 2086, 2095, 2099, 21, 210, 2105, 2109, 211, 212, 213, 213LC, 214, ...] |
| 3 | fiSecondaryDesc | [ MSR SPIN ACE, #NAME?, -2, -3, -5, -5L, -6, -7, 0.7, 1, 2, 3, 5, 7, A, AA, AB, AG, AW, AX, B, B , BEC, BL, BLGP, BLGPPS, BZ, BZD, C, C , CE, CH, CK, CKB, CL, CLR, CM, CR, CS, CX, D, DC, DL, DT, DX, DXT, DZ, E, EG, EL, ESS, EST, EW, EX, F, FR, G, GT, H, H , H90, HAG, HD, HDS, HDSL, HF, HL, HLGP, HLS, HX, HZ, IV, J, JX, K, L, LC, LC7A, LC7LR, LCD, LCH, LCLR, LCM, LD, LE, LGP, LR, LS, LT, LX, M, M , MC, MR, MRX, MSR, MSR SPIN ACE, MT, MU, MXT, ...] |
| 4 | fiModelSeries | [ III, #NAME?, -1, -1.50E+01, -11, -12, -15, -16, -17, -18, -1B, -1C, -1L, -2, -20, -21, -21A, -2A, -2C, -2E, -2LC, -2N, -3, -3C, -3EO, -3H, -3L, -3LC, -3LK, -3M, -3MC, -3PT, -4, -5, -5A, -5E, -5F, -5H, -5L, -5LC, -6, -6A, -6B, -6C, -6E, -6K, -6LC, -6LK, -7, -7B, -7E, -7K, -8, -8E, 1, 12, 14FT, 15, 16, 17, 18, 1970, 2, 20, 21KomStat, 21KomStatII, 22, 2B, 2T, 3, 3A, 3C, 4, 5, 5N, 6, 6.00E+00, 6F, 6L, 6LE, 6LK, 7, 7.00E+00, 7A, 7L, 8, A, AWS, D, D7, E, EX, Elite, FASTRRACK, G, GALEO, H, II, III, IV, ...] |
| 5 | fiModelDescriptor | [ 14FT, LGP, SUPER, XLT, XT, ZX, (BLADE RUNNER), 1, 2, 2.00E+00, 2N, 3, 3.00E+00, 3C, 3L, 3NO, 4WD, 4x4x4, 5, 6, 6K, 7, 7.00E+00, 7A, 8, A, AE0, AVANCE, B, BE, C, CK, CR, CRSB, CUSTOM, DA, DELUXE, DHP, DINGO, DLL, DT, DW, E, ESL, G, GALEO, H, H5, HD, HF, HSD, HT, High Lift, HighLift, II, III, IT, IV, K, K3, K5, KA, KBNA, L, LC, LC8, LCH, LCR, LCRTS, LE, LGP, LGPVP, LITRONIC, LK, LL, LM, LN, LR, LRC, LRR, LS, LT, LU, LX, LongReach, M, MC, ME, MH, N, NLC, NSUC, P, PLUS, PRO, RR, RTS, S, SA, SB, ...] |
| 6 | ProductSize | [Compact, Large, Large / Medium, Medium, Mini, Small] |
| 7 | fiProductClassDesc | [Backhoe Loader - 0.0 to 14.0 Ft Standard Digging Depth, Backhoe Loader - 14.0 to 15.0 Ft Standard Digging Depth, Backhoe Loader - 15.0 to 16.0 Ft Standard Digging Depth, Backhoe Loader - 16.0 + Ft Standard Digging Depth, Backhoe Loader - Unidentified, Hydraulic Excavator, Track - 0.0 to 2.0 Metric Tons, Hydraulic Excavator, Track - 11.0 to 12.0 Metric Tons, Hydraulic Excavator, Track - 12.0 to 14.0 Metric Tons, Hydraulic Excavator, Track - 14.0 to 16.0 Metric Tons, Hydraulic Excavator, Track - 150.0 to 300.0 Metric Tons, Hydraulic Excavator, Track - 16.0 to 19.0 Metric Tons, Hydraulic Excavator, Track - 19.0 to 21.0 Metric Tons, Hydraulic Excavator, Track - 2.0 to 3.0 Metric Tons, Hydraulic Excavator, Track - 21.0 to 24.0 Metric Tons, Hydraulic Excavator, Track - 24.0 to 28.0 Metric Tons, Hydraulic Excavator, Track - 28.0 to 33.0 Metric Tons, Hydraulic Excavator, Track - 3.0 to 4.0 Metric Tons, Hydraulic Excavator, Track - 300.0 + Metric Tons, Hydraulic Excavator, Track - 33.0 to 40.0 Metric Tons, Hydraulic Excavator, Track - 4.0 to 5.0 Metric Tons, Hydraulic Excavator, Track - 4.0 to 6.0 Metric Tons, Hydraulic Excavator, Track - 40.0 to 50.0 Metric Tons, Hydraulic Excavator, Track - 5.0 to 6.0 Metric Tons, Hydraulic Excavator, Track - 50.0 to 66.0 Metric Tons, Hydraulic Excavator, Track - 6.0 to 8.0 Metric Tons, Hydraulic Excavator, Track - 66.0 to 90.0 Metric Tons, Hydraulic Excavator, Track - 8.0 to 11.0 Metric Tons, Hydraulic Excavator, Track - 90.0 to 150.0 Metric Tons, Hydraulic Excavator, Track - Unidentified, Hydraulic Excavator, Track - Unidentified (Compact Construction), Motorgrader - 130.0 to 145.0 Horsepower, Motorgrader - 145.0 to 170.0 Horsepower, Motorgrader - 170.0 to 200.0 Horsepower, Motorgrader - 200.0 + Horsepower, Motorgrader - 45.0 to 130.0 Horsepower, Motorgrader - Unidentified, Skid Steer Loader - 0.0 to 701.0 Lb Operating Capacity, Skid Steer Loader - 1251.0 to 1351.0 Lb Operating Capacity, Skid Steer Loader - 1351.0 to 1601.0 Lb Operating Capacity, Skid Steer Loader - 1601.0 to 1751.0 Lb Operating Capacity, Skid Steer Loader - 1751.0 to 2201.0 Lb Operating Capacity, Skid Steer Loader - 2201.0 to 2701.0 Lb Operating Capacity, Skid Steer Loader - 2701.0+ Lb Operating Capacity, Skid Steer Loader - 701.0 to 976.0 Lb Operating Capacity, Skid Steer Loader - 976.0 to 1251.0 Lb Operating Capacity, Skid Steer Loader - Unidentified, Track Type Tractor, Dozer - 105.0 to 130.0 Horsepower, Track Type Tractor, Dozer - 130.0 to 160.0 Horsepower, Track Type Tractor, Dozer - 160.0 to 190.0 Horsepower, Track Type Tractor, Dozer - 190.0 to 260.0 Horsepower, Track Type Tractor, Dozer - 20.0 to 75.0 Horsepower, Track Type Tractor, Dozer - 260.0 + Horsepower, Track Type Tractor, Dozer - 75.0 to 85.0 Horsepower, Track Type Tractor, Dozer - 85.0 to 105.0 Horsepower, Track Type Tractor, Dozer - Unidentified, Wheel Loader - 0.0 to 40.0 Horsepower, Wheel Loader - 100.0 to 110.0 Horsepower, Wheel Loader - 1000.0 + Horsepower, Wheel Loader - 110.0 to 120.0 Horsepower, Wheel Loader - 120.0 to 135.0 Horsepower, Wheel Loader - 135.0 to 150.0 Horsepower, Wheel Loader - 150.0 to 175.0 Horsepower, Wheel Loader - 175.0 to 200.0 Horsepower, Wheel Loader - 200.0 to 225.0 Horsepower, Wheel Loader - 225.0 to 250.0 Horsepower, Wheel Loader - 250.0 to 275.0 Horsepower, Wheel Loader - 275.0 to 350.0 Horsepower, Wheel Loader - 350.0 to 500.0 Horsepower, Wheel Loader - 40.0 to 60.0 Horsepower, Wheel Loader - 500.0 to 1000.0 Horsepower, Wheel Loader - 60.0 to 80.0 Horsepower, Wheel Loader - 80.0 to 90.0 Horsepower, Wheel Loader - 90.0 to 100.0 Horsepower, Wheel Loader - Unidentified] |
| 8 | state | [Alabama, Alaska, Arizona, Arkansas, California, Colorado, Connecticut, Delaware, Florida, Georgia, Hawaii, Idaho, Illinois, Indiana, Iowa, Kansas, Kentucky, Louisiana, Maine, Maryland, Massachusetts, Michigan, Minnesota, Mississippi, Missouri, Montana, Nebraska, Nevada, New Hampshire, New Jersey, New Mexico, New York, North Carolina, North Dakota, Ohio, Oklahoma, Oregon, Pennsylvania, Puerto Rico, Rhode Island, South Carolina, South Dakota, Tennessee, Texas, Unspecified, Utah, Vermont, Virginia, Washington, Washington DC, West Virginia, Wisconsin, Wyoming] |
| 9 | ProductGroup | [BL, MG, SSL, TEX, TTT, WL] |
| 10 | ProductGroupDesc | [Backhoe Loaders, Motor Graders, Skid Steer Loaders, Track Excavators, Track Type Tractors, Wheel Loader] |
| 11 | Drive_System | [All Wheel Drive, Four Wheel Drive, No, Two Wheel Drive] |
| 12 | Enclosure | [EROPS, EROPS AC, EROPS w AC, NO ROPS, None or Unspecified, OROPS] |
| 13 | Forks | [None or Unspecified, Yes] |
| 14 | Pad_Type | [Grouser, None or Unspecified, Reversible, Street] |
| 15 | Ride_Control | [No, None or Unspecified, Yes] |
| 16 | Stick | [Extended, Standard] |
| 17 | Transmission | [AutoShift, Autoshift, Direct Drive, Hydrostatic, None or Unspecified, Powershift, Powershuttle, Standard] |
| 18 | Turbocharged | [None or Unspecified, Yes] |
| 19 | Blade_Extension | [None or Unspecified, Yes] |
| 20 | Blade_Width | [12', 13', 14', 16', <12', None or Unspecified] |
| 21 | Enclosure_Type | [High Profile, Low Profile, None or Unspecified] |
| 22 | Engine_Horsepower | [No, Variable] |
| 23 | Hydraulics | [2 Valve, 3 Valve, 4 Valve, Auxiliary, Base + 1 Function, Base + 2 Function, Base + 3 Function, Base + 4 Function, Base + 5 Function, Base + 6 Function, None or Unspecified, Standard] |
| 24 | Pushblock | [None or Unspecified, Yes] |
| 25 | Ripper | [Multi Shank, None or Unspecified, Single Shank, Yes] |
| 26 | Scarifier | [None or Unspecified, Yes] |
| 27 | Tip_Control | [None or Unspecified, Sideshift & Tip, Tip] |
| 28 | Tire_Size | [10 inch, 10", 13", 14", 15.5, 15.5", 17.5, 17.5", 20.5, 20.5", 23.1", 23.5, 23.5", 26.5, 29.5, 7.0", None or Unspecified] |
| 29 | Coupler | [Hydraulic, Manual, None or Unspecified] |
| 30 | Coupler_System | [None or Unspecified, Yes] |
| 31 | Grouser_Tracks | [None or Unspecified, Yes] |
| 32 | Hydraulics_Flow | [High Flow, None or Unspecified, Standard] |
| 33 | Track_Type | [Rubber, Steel] |
| 34 | Undercarriage_Pad_Width | [14 inch, 15 inch, 16 inch, 18 inch, 20 inch, 22 inch, 24 inch, 25 inch, 26 inch, 27 inch, 28 inch, 30 inch, 31 inch, 31.5 inch, 32 inch, 33 inch, 34 inch, 36 inch, None or Unspecified] |
| 35 | Stick_Length | [10' 10", 10' 2", 10' 6", 11' 0", 11' 10", 12' 10", 12' 4", 12' 8", 13' 10", 13' 7", 13' 9", 14' 1", 15' 4", 15' 9", 19' 8", 24' 3", 6' 3", 7' 10", 8' 10", 8' 2", 8' 4", 8' 6", 9' 10", 9' 2", 9' 5", 9' 6", 9' 7", 9' 8", None or Unspecified] |
| 36 | Thumb | [Hydraulic, Manual, None or Unspecified] |
| 37 | Pattern_Changer | [No, None or Unspecified, Yes] |
| 38 | Grouser_Type | [Double, Single, Triple] |
| 39 | Backhoe_Mounting | [None or Unspecified, Yes] |
| 40 | Blade_Type | [Angle, Coal, Landfill, No, None or Unspecified, PAT, Semi U, Straight, U, VPAT] |
| 41 | Travel_Controls | [1 Speed, 2 Pedal, Differential Steer, Finger Tip, Lever, None or Unspecified, Pedal] |
| 42 | Differential_Type | [Limited Slip, Locking, No Spin, Standard] |
| 43 | Steering_Controls | [Command Control, Conventional, Four Wheel Standard, No, Wheel] |
updates = {
'UsageBand':['High', 'Medium', 'Low'],
'Blade_Width':[ "16'", "14'", "13'","12'", "<12'", "None or Unspecified"],
'Grouser_Type':['Triple', 'Double', 'Single'],
'ProductSize':['Large','Large / Medium', 'Medium', 'Compact', 'Small', 'Mini']
}
cat_dict.update(updates)
filter_dict = {k:v for k,v in cat_dict.items() if k in updates}
display_cat(filter_dict)| 0 | 1 | |
|---|---|---|
| 0 | UsageBand | [High, Medium, Low] |
| 1 | ProductSize | [Large, Large / Medium, Medium, Compact, Small, Mini] |
| 2 | Blade_Width | [16', 14', 13', 12', <12', None or Unspecified] |
| 3 | Grouser_Type | [Triple, Double, Single] |
Define Validation Set
Code
def range_data(df_train, df_test, names=['Train', 'Test'], datecol='saledate'):
return pd.DataFrame([
{'Name':names[0], 'Start':df_train[datecol].min(), 'End': df_train[datecol].max(), 'Interval':df_train[datecol].max() -df_train[datecol].min(), 'Size': len(df_train) },
{'Name':names[1], 'Start':df_test[datecol].min(), 'End': df_test[datecol].max(), 'Interval':df_test[datecol].max() -df_test[datecol].min(), 'Size': len(df_test) }]).set_index('Name')range_data(df_train, df_test)| Start | End | Interval | Size | |
|---|---|---|---|---|
| Name | ||||
| Train | 1989-01-17 | 2011-12-30 | 8382 days | 401125 |
| Test | 2012-01-01 | 2012-04-28 | 118 days | 11573 |
Test data starts at the end of train date with about 4 months of data (covering February with 28/29 days). We need to split our internal validation set in a similar way. We will take 4 months / 120 days of data as validation set
validation_date_start = (df_train[['saledate']].max() - pd.Timedelta(value=120, unit='D')).values[0] # Last 4 months data for internal validation
df_model, df_valid = df_train[df_train['saledate'] < validation_date_start], df_train[df_train['saledate']>= validation_date_start]range_data(df_model, df_valid, names=['Model', 'Valid'])| Start | End | Interval | Size | |
|---|---|---|---|---|
| Name | ||||
| Model | 1989-01-17 | 2011-08-31 | 8261 days | 390213 |
| Valid | 2011-09-01 | 2011-12-30 | 120 days | 10912 |
Define Pipeline
def get_model_pipeline(max_n_cat=0,
cat_dict=None,
scale_dict={'class': StandardScaler},
cat_num_dict={'class':NumericalEncoder,'categories':None},
cat_dummy_dict={'class':OneHotEncoder,'handle_unknown':'ignore'},
imputer_dict={'class':SimpleImputer, 'strategy':'median'},
):
layer_spec_default = (get_default_feature_def,
{
'skip_flds':None,
'ignored_flds':None,
'max_n_cat':max_n_cat,
'na_exclude_cols':[],
'scale_var_num':True,
'scale_var_cat':False,
'scale_dict':scale_dict,
'cat_num_dict':cat_num_dict,
'cat_dummy_dict':cat_dummy_dict,
'imputer_dict':imputer_dict,
'include_time_cols':True,
'keep_dt_cols':False,
'cat_dict':cat_dict
}
)
layer_specs = [layer_spec_default]
proc = Proc(layer_specs=layer_specs); #proc.fit_transform(X)
model = RandomForestRegressor(n_jobs=-1)
pipeline = make_pipeline(proc, model); pipeline
return pipelinepipeline = get_model_pipeline(cat_dict); pipelinePipeline(steps=[('proc', <aiking.ml.structured.Proc object>),
('randomforestregressor', RandomForestRegressor(n_jobs=-1))])Train on Partial Data
max_n_cat = 0
def get_xy(df, col='SalePrice'): return df.drop([col], axis=1), np.log(df[col])
df = df_model.sample(frac=0.04)
X, y = get_xy(df)
X_model, y_model = get_xy(df_model)
X_valid, y_valid = get_xy(df_valid)
pipeline = get_model_pipeline(max_n_cat,cat_dict)
pipeline.fit(X, y)Pipeline(steps=[('proc', <aiking.ml.structured.Proc object>),
('randomforestregressor', RandomForestRegressor(n_jobs=-1))])get_score(pipeline, X, y, X_valid, y_valid, scorers=get_scorer_dict())| Training | Validation | |
|---|---|---|
| Metric | ||
| r2 | 0.978088 | 0.821789 |
| neg_root_mean_squared_error | -0.102343 | -0.305869 |
| explained_variance | 0.978089 | 0.825985 |
| neg_median_absolute_error | -0.055909 | -0.181245 |
| neg_mean_absolute_percentage_error | -0.007455 | -0.022704 |
get_score(pipeline, X_model, y_model, X_valid, y_valid, scorers=get_scorer_dict())| Training | Validation | |
|---|---|---|
| Metric | ||
| r2 | 0.853482 | 0.821789 |
| neg_root_mean_squared_error | -0.265110 | -0.305869 |
| explained_variance | 0.853483 | 0.825985 |
| neg_median_absolute_error | -0.144865 | -0.181245 |
| neg_mean_absolute_percentage_error | -0.019361 | -0.022704 |
This gives an indication of estimate of msle around .26 to .30[Really 0.304 from validation estimate]
Cross validation estimate
df_cv = timeseries_cv(df_model, 'saledate', 'SalePrice',
pipeline_callback_dict={'func': get_model_pipeline, 'func_kwargs':{'max_n_cat':0, 'cat_dict':cat_dict}},
y_mod_func=np.log,
scorers = get_scorer_dict(),
n_train=15000, n_test=12000, n_splits=10)
df_cv
100.00% [10/10 01:06<00:00]
| Training | Validation | set | train_start | train_end | valid_start | valid_end | |
|---|---|---|---|---|---|---|---|
| Metric | |||||||
| r2 | 0.986050 | 0.855443 | 1 | 2008-02-26 | 2008-06-28 | 2008-06-28 | 2008-11-07 |
| neg_root_mean_squared_error | -0.082520 | -0.262933 | 1 | 2008-02-26 | 2008-06-28 | 2008-06-28 | 2008-11-07 |
| explained_variance | 0.986051 | 0.863314 | 1 | 2008-02-26 | 2008-06-28 | 2008-06-28 | 2008-11-07 |
| neg_median_absolute_error | -0.037583 | -0.148024 | 1 | 2008-02-26 | 2008-06-28 | 2008-06-28 | 2008-11-07 |
| neg_mean_absolute_percentage_error | -0.005600 | -0.019542 | 1 | 2008-02-26 | 2008-06-28 | 2008-06-28 | 2008-11-07 |
| r2 | 0.984919 | 0.839832 | 2 | 2008-02-26 | 2008-11-07 | 2008-11-07 | 2009-02-16 |
| neg_root_mean_squared_error | -0.085098 | -0.280481 | 2 | 2008-02-26 | 2008-11-07 | 2008-11-07 | 2009-02-16 |
| explained_variance | 0.984919 | 0.865230 | 2 | 2008-02-26 | 2008-11-07 | 2008-11-07 | 2009-02-16 |
| neg_median_absolute_error | -0.040576 | -0.167759 | 2 | 2008-02-26 | 2008-11-07 | 2008-11-07 | 2009-02-16 |
| neg_mean_absolute_percentage_error | -0.005859 | -0.021296 | 2 | 2008-02-26 | 2008-11-07 | 2008-11-07 | 2009-02-16 |
| r2 | 0.985811 | 0.855938 | 3 | 2008-02-26 | 2009-02-16 | 2009-02-16 | 2009-05-05 |
| neg_root_mean_squared_error | -0.083452 | -0.268049 | 3 | 2008-02-26 | 2009-02-16 | 2009-02-16 | 2009-05-05 |
| explained_variance | 0.985812 | 0.870222 | 3 | 2008-02-26 | 2009-02-16 | 2009-02-16 | 2009-05-05 |
| neg_median_absolute_error | -0.039221 | -0.161301 | 3 | 2008-02-26 | 2009-02-16 | 2009-02-16 | 2009-05-05 |
| neg_mean_absolute_percentage_error | -0.005723 | -0.020529 | 3 | 2008-02-26 | 2009-02-16 | 2009-02-16 | 2009-05-05 |
| r2 | 0.986149 | 0.859721 | 4 | 2008-02-29 | 2009-05-05 | 2009-05-05 | 2009-08-19 |
| neg_root_mean_squared_error | -0.082841 | -0.263684 | 4 | 2008-02-29 | 2009-05-05 | 2009-05-05 | 2009-08-19 |
| explained_variance | 0.986149 | 0.860370 | 4 | 2008-02-29 | 2009-05-05 | 2009-05-05 | 2009-08-19 |
| neg_median_absolute_error | -0.039276 | -0.152460 | 4 | 2008-02-29 | 2009-05-05 | 2009-05-05 | 2009-08-19 |
| neg_mean_absolute_percentage_error | -0.005729 | -0.019758 | 4 | 2008-02-29 | 2009-05-05 | 2009-05-05 | 2009-08-19 |
| r2 | 0.985700 | 0.864896 | 5 | 2008-03-05 | 2009-08-19 | 2009-08-19 | 2009-12-04 |
| neg_root_mean_squared_error | -0.084180 | -0.254076 | 5 | 2008-03-05 | 2009-08-19 | 2009-08-19 | 2009-12-04 |
| explained_variance | 0.985700 | 0.864995 | 5 | 2008-03-05 | 2009-08-19 | 2009-08-19 | 2009-12-04 |
| neg_median_absolute_error | -0.040860 | -0.144788 | 5 | 2008-03-05 | 2009-08-19 | 2009-08-19 | 2009-12-04 |
| neg_mean_absolute_percentage_error | -0.005935 | -0.018973 | 5 | 2008-03-05 | 2009-08-19 | 2009-08-19 | 2009-12-04 |
| r2 | 0.984630 | 0.847664 | 6 | 2008-05-01 | 2009-12-04 | 2009-12-04 | 2010-03-30 |
| neg_root_mean_squared_error | -0.086090 | -0.272201 | 6 | 2008-05-01 | 2009-12-04 | 2009-12-04 | 2010-03-30 |
| explained_variance | 0.984633 | 0.855422 | 6 | 2008-05-01 | 2009-12-04 | 2009-12-04 | 2010-03-30 |
| neg_median_absolute_error | -0.040860 | -0.155152 | 6 | 2008-05-01 | 2009-12-04 | 2009-12-04 | 2010-03-30 |
| neg_mean_absolute_percentage_error | -0.005967 | -0.019876 | 6 | 2008-05-01 | 2009-12-04 | 2009-12-04 | 2010-03-30 |
| r2 | 0.985190 | 0.843297 | 7 | 2008-05-15 | 2010-03-30 | 2010-03-30 | 2010-08-24 |
| neg_root_mean_squared_error | -0.084891 | -0.278687 | 7 | 2008-05-15 | 2010-03-30 | 2010-03-30 | 2010-08-24 |
| explained_variance | 0.985192 | 0.844513 | 7 | 2008-05-15 | 2010-03-30 | 2010-03-30 | 2010-08-24 |
| neg_median_absolute_error | -0.039577 | -0.151982 | 7 | 2008-05-15 | 2010-03-30 | 2010-03-30 | 2010-08-24 |
| neg_mean_absolute_percentage_error | -0.005821 | -0.020361 | 7 | 2008-05-15 | 2010-03-30 | 2010-03-30 | 2010-08-24 |
| r2 | 0.984002 | 0.871116 | 8 | 2008-11-12 | 2010-08-24 | 2010-08-24 | 2011-01-26 |
| neg_root_mean_squared_error | -0.088833 | -0.253561 | 8 | 2008-11-12 | 2010-08-24 | 2010-08-24 | 2011-01-26 |
| explained_variance | 0.984003 | 0.871649 | 8 | 2008-11-12 | 2010-08-24 | 2010-08-24 | 2011-01-26 |
| neg_median_absolute_error | -0.043196 | -0.143973 | 8 | 2008-11-12 | 2010-08-24 | 2010-08-24 | 2011-01-26 |
| neg_mean_absolute_percentage_error | -0.006185 | -0.018764 | 8 | 2008-11-12 | 2010-08-24 | 2010-08-24 | 2011-01-26 |
| r2 | 0.985709 | 0.859266 | 9 | 2009-02-16 | 2011-01-26 | 2011-01-26 | 2011-04-28 |
| neg_root_mean_squared_error | -0.084228 | -0.265014 | 9 | 2009-02-16 | 2011-01-26 | 2011-01-26 | 2011-04-28 |
| explained_variance | 0.985709 | 0.867493 | 9 | 2009-02-16 | 2011-01-26 | 2011-01-26 | 2011-04-28 |
| neg_median_absolute_error | -0.041602 | -0.146238 | 9 | 2009-02-16 | 2011-01-26 | 2011-01-26 | 2011-04-28 |
| neg_mean_absolute_percentage_error | -0.005938 | -0.019083 | 9 | 2009-02-16 | 2011-01-26 | 2011-01-26 | 2011-04-28 |
| r2 | 0.986866 | 0.860514 | 10 | 2009-05-06 | 2011-04-28 | 2011-04-28 | 2011-08-31 |
| neg_root_mean_squared_error | -0.081017 | -0.263815 | 10 | 2009-05-06 | 2011-04-28 | 2011-04-28 | 2011-08-31 |
| explained_variance | 0.986871 | 0.860803 | 10 | 2009-05-06 | 2011-04-28 | 2011-04-28 | 2011-08-31 |
| neg_median_absolute_error | -0.037374 | -0.151020 | 10 | 2009-05-06 | 2011-04-28 | 2011-04-28 | 2011-08-31 |
| neg_mean_absolute_percentage_error | -0.005516 | -0.019471 | 10 | 2009-05-06 | 2011-04-28 | 2011-04-28 | 2011-08-31 |
df_cv.loc['neg_root_mean_squared_error'][['train_end', 'Training', 'Validation']].set_index('train_end').plot()<AxesSubplot:xlabel='train_end'>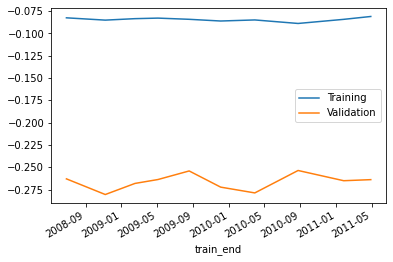
df_cv.loc['neg_root_mean_squared_error'][[ 'Validation']].mean()Validation -0.26625
dtype: float64Tuning
Number of points to select for training to improve validation
This requires little bit of playing with how many points to choose for training
n = 8000
df_model_train = df_model.sort_values(by='saledate').iloc[-n:]
df_model_train.sample(frac=1)
X_model_train , y_model_train = get_xy(df_model_train)
pipeline = get_model_pipeline(max_n_cat, cat_dict)
pipeline.fit(X_model_train, y_model_train)
score_df = get_score(pipeline, X_model_train, y_model_train, X_valid, y_valid, scorers=get_scorer_dict())
score_df['n'] = n
score_df| Training | Validation | n | |
|---|---|---|---|
| Metric | |||
| r2 | 0.986471 | 0.848635 | 8000 |
| neg_root_mean_squared_error | -0.081511 | -0.281891 | 8000 |
| explained_variance | 0.986471 | 0.849255 | 8000 |
| neg_median_absolute_error | -0.038784 | -0.157271 | 8000 |
| neg_mean_absolute_percentage_error | -0.005624 | -0.020596 | 8000 |
np.linspace(20000, 5000,16)array([20000., 19000., 18000., 17000., 16000., 15000., 14000., 13000.,
12000., 11000., 10000., 9000., 8000., 7000., 6000., 5000.])def get_score_for_n(n=8000):
df_model_train = df_model.sort_values(by='saledate').iloc[-n:]
df_model_train.sample(frac=1)
X_model_train , y_model_train = get_xy(df_model_train)
pipeline = get_model_pipeline(max_n_cat, cat_dict)
pipeline.fit(X_model_train, y_model_train)
score_df = get_score(pipeline, X_model_train, y_model_train, X_valid, y_valid, scorers=get_scorer_dict())
score_df['n'] = n
return score_dfscores = pd.concat([get_score_for_n(n=int(n)) for n in np.linspace(20000, 5000,16)]); scores| Training | Validation | n | |
|---|---|---|---|
| Metric | |||
| r2 | 0.987612 | 0.869907 | 20000 |
| neg_root_mean_squared_error | -0.078250 | -0.261333 | 20000 |
| explained_variance | 0.987613 | 0.870216 | 20000 |
| neg_median_absolute_error | -0.037010 | -0.147194 | 20000 |
| neg_mean_absolute_percentage_error | -0.005343 | -0.019104 | 20000 |
| ... | ... | ... | ... |
| r2 | 0.985790 | 0.833147 | 5000 |
| neg_root_mean_squared_error | -0.083945 | -0.295961 | 5000 |
| explained_variance | 0.985790 | 0.834022 | 5000 |
| neg_median_absolute_error | -0.038053 | -0.166622 | 5000 |
| neg_mean_absolute_percentage_error | -0.005691 | -0.021768 | 5000 |
80 rows × 3 columns
scores.loc['neg_root_mean_squared_error']| Training | Validation | n | |
|---|---|---|---|
| Metric | |||
| neg_root_mean_squared_error | -0.078250 | -0.261333 | 20000 |
| neg_root_mean_squared_error | -0.078630 | -0.260586 | 19000 |
| neg_root_mean_squared_error | -0.079291 | -0.261858 | 18000 |
| neg_root_mean_squared_error | -0.080207 | -0.262133 | 17000 |
| neg_root_mean_squared_error | -0.080376 | -0.265427 | 16000 |
| neg_root_mean_squared_error | -0.081357 | -0.265461 | 15000 |
| neg_root_mean_squared_error | -0.081260 | -0.267446 | 14000 |
| neg_root_mean_squared_error | -0.080965 | -0.270179 | 13000 |
| neg_root_mean_squared_error | -0.080303 | -0.270147 | 12000 |
| neg_root_mean_squared_error | -0.081419 | -0.273167 | 11000 |
| neg_root_mean_squared_error | -0.081806 | -0.276547 | 10000 |
| neg_root_mean_squared_error | -0.081851 | -0.279289 | 9000 |
| neg_root_mean_squared_error | -0.082139 | -0.281973 | 8000 |
| neg_root_mean_squared_error | -0.081183 | -0.284795 | 7000 |
| neg_root_mean_squared_error | -0.081215 | -0.285585 | 6000 |
| neg_root_mean_squared_error | -0.083945 | -0.295961 | 5000 |
Conclusion is we can try 2 models
- Add 19000 points from df_model with df_valid
- Add df_model with df_valid and take last 19000 points
Predictions
df_model_train = df_model.sort_values(by='saledate').iloc[-19000:]
df_sel_train = pd.concat([df_model_train, df_valid])
df_sel_train.sample(frac=1)
X_sel_train, y_sel_train = get_xy(df_sel_train)
pipeline = get_model_pipeline(max_n_cat, cat_dict)
pipeline.fit(X_sel_train, y_sel_train)Pipeline(steps=[('proc', <aiking.ml.structured.Proc object>),
('randomforestregressor', RandomForestRegressor(n_jobs=-1))])plt.hist(np.exp(y_sel_train))(array([10186., 8235., 4265., 2565., 1941., 1222., 922., 350.,
166., 60.]),
array([ 4750., 18475., 32200., 45925., 59650., 73375., 87100.,
100825., 114550., 128275., 142000.]),
<BarContainer object of 10 artists>)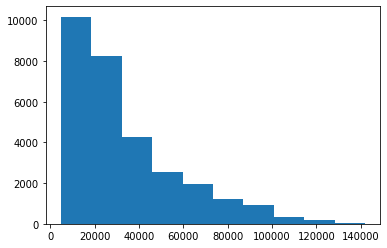
plt.hist(np.exp(pipeline.predict(df_test)))(array([3914., 2885., 1674., 1086., 809., 575., 409., 141., 48.,
32.]),
array([ 5632.98698052, 17963.68207264, 30294.37716476, 42625.07225689,
54955.76734901, 67286.46244114, 79617.15753326, 91947.85262538,
104278.54771751, 116609.24280963, 128939.93790175]),
<BarContainer object of 10 artists>)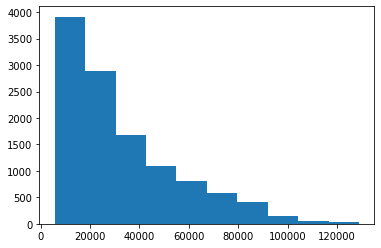
df_submission = pd.DataFrame()
df_submission['Id'] = df_test['SalesID']
df_submission['Predicted'] = np.exp(pipeline.predict(df_test))
df_submission.to_csv('submission.csv', index=False)if not is_kaggle:
import kaggle
from aiking.integrations.kaggle import push2kaggle
# kaggle.api.competition_submit_cli("submission.csv", "Submission from local machine", competition="bluebook-bulldozer-remix")
push2kaggle("00_index.ipynb")